
from fastai.vision.all import *
import pdb
LSH is an algorithm for clustering of high dimensional data. There are several ways of implementing the algorithm. We'll look at random projections and random rotations.
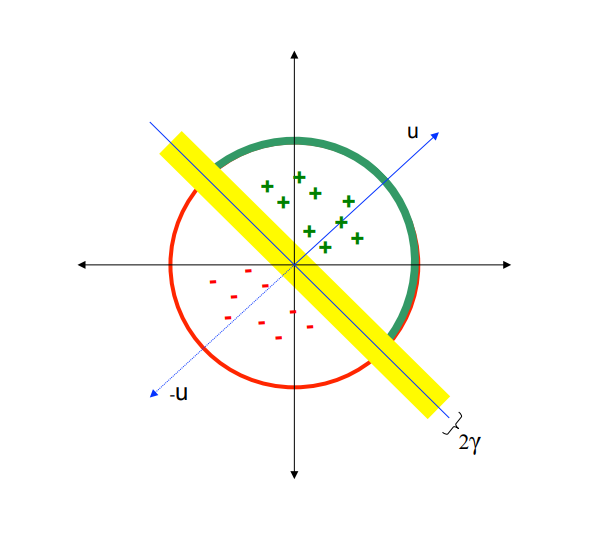
Yannick explains LSH with random projections, and the same with this blog post. That means that in a 2D case we can envision lines drawn at random, and points grouped depending on if they point in a similar direction or not. This method is probabilistic as points that are close can end up in different buckets by chance, but they will have a high probability of beeing grouped to gether. Illustration from the blog:
We'll demonstrate random projections for the 2 dimensional case. First we fix some points in the 2d plane. We'll do everything deterministically to begin with:
points = np.array([[0.9, 1],
[-0.9, -1],
[0.5, -.5]])
fig ,ax = plt.subplots()
for (x, y),c in zip(points, ['r', 'b', 'g']):
ax.scatter(x, y, c=c)
ax.grid();

Next we make a vector assumed to pass thru the origin. We'll make it a positive unit vector so we can think of it pointing up and to the right. We can manually project this vector from say x = [-1, 1] and display it as a line:
u = np.array([1, 1])
ax.plot([-1, 1], [-1, 1])
fig

The dot product between vectors a and b is the lenght of a projected onto b multiplied with the length of b. So if two vectors point in the same direction their dot product is positive and vice versa. If vectors are perpendicular the dot product is 0. The doproduct is defined by summing up the pairwise products of two vectors. Note that we can think of our points as vectors from the origin. Taking the dot product of the red point and u, we get as expected a postivite dotproduct:
(points[0]*u).sum()
We can calculate the dotproduct for all our points by matrix multiplication. The red vector points along u, the blue opposite, and the green on is perpendicular:
points@u.T
We can generalize this in a function by adding randomness, and only keeping the sign of the dotproduct.
def rand_proj(points):
u = np.random.randn(1,2) # 1 projection in 2-dim
dots = points@u.T
return np.sign(dots)
rand_proj(points)
In this case we have two buckets, -1 and 1
We can also repeat the bucketing process n times to get a more stable estimate. Each run will produce a different results. Eg. the first column below represents a new hash bucket for the red point.
[rand_proj(points).squeeze() for _ in range(5)]
We can also generalize this to produce more than two buckets. The number of buckets is 2x the number of random projections:
def rand_proj(points, n_projections=2, n_dim=2):
u = np.random.randn(n_projections, n_dim)
dots = points@u.T
return np.sign(dots)
rand_proj(points, n_projections=2)
In this case we have 4 buckets: [-1,-1], [-1,1], [1,-1], [1,1]. Which could be further combined into a single id [0,1,2,3]
The paper instead opts for an angular interpretation of LSH:
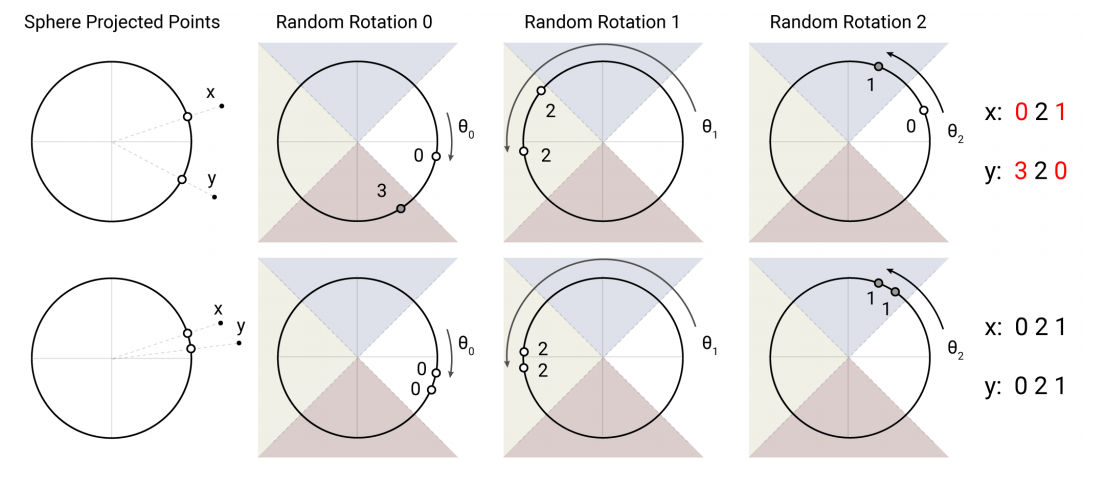
In the 2d case each point is projected onto a unit sphere, and then rotated randomly. Bucketing will depend on which of the sectors it ends up in. The algorithm is decribed as:
To get b hashes, we first fix a random matrix R of size [dk, b/2]. We then define h(x) = arg max([xR; −xR]) where [u; v] denotes the concatenation of two vectors. This method is a known LSH scheme (Andoni et al., 2015) and is easy to implement and apply to batches of vectors.
The blog has an implementation to compute a single hash wich follows these steps.
def rand_rotations(x, hidden_dim, n_buckets):
random_rotations = np.random.randn(hidden_dim, n_buckets // 2)
rotated_vectors = np.dot(x, random_rotations)
rotated_vectors = np.hstack([rotated_vectors, -rotated_vectors])
return np.argmax(rotated_vectors, axis=-1)
rand_rotations(points, hidden_dim=2, n_buckets=4)
This has the nice property of directly giving us the hash-bucket id instead of our list above. The next step will be to scale the algorithm to do several rounds. One could simply loop it, but it will be more effectient to add an extra dimension to our matrices. We will also need to take care of batch and attention head dimensions.
from einops import rearrange, repeat, reduce
The code for the LSH algorithm used for the paper can be found in the trax library. Lucidrains also has a stripped down version. We'll base our algorithm on lucidrains, but simplify even further to make the algorithm as clear as possible:
- we'll assume rehashing each round as in trax library
- no dropout on the vectors to be hashed.
- won't pay attention to device at the moment
- assume correct dytpes passed in
- similar number of rotations per head
That means we have to:
- Keep track of the various dimension
- perform the random_rotations part of the algorithm (as above)
- Structure the output depending on number of rounds and buckets
def hash_vectors(vecs, n_buckets=2, n_rounds=1):
# 1. account for the input shapes. vecs = [bs, sl, hidden_dim]
assert n_buckets % 2 == 0
batch_size, _, hidden_dim = vecs.shape
rotations_shape = (hidden_dim, n_rounds, n_buckets // 2)
# 2. get the dotproduct, cat and argmax like in the section above
random_rotations = repeat(torch.randn(rotations_shape), #repeat rotations accross the batch dimension
'h nr nb -> bs h nr nb', bs=batch_size)
rotated_vecs = torch.einsum('bsh,bhrn->brsn',
vecs, # [bs, sl, hidden_dim]
random_rotations) # [bs, hidden_dim, n_rounds, n_buckets//2]
# rotated vecs: [bs, n_rounds, sl, n_buckets//2]
rotated_vecs = torch.cat([rotated_vecs, -rotated_vecs], dim=-1) # [bs, n_rounds, sl, n_buckets]
buckets = torch.argmax(rotated_vecs, dim=-1) # [bs, n_rounds, sl]
# 3. Next we add offsets so that bucket numbers from different hashing rounds don't overlap.
offsets = torch.arange(n_rounds) # list of [0,1,2,..n_rounds-1]
offsets = rearrange(offsets * n_buckets, '(r)-> (1)(r)(1)') # [1, n_rounds, 1]
buckets = rearrange(buckets+offsets, 'bs r sl -> bs (r sl)') # [bs, (n_rounds*sl)]
return buckets
Let's pass our trusty old points in, but first convert to tensors, and create a batch dimension first.
t = torch.tensor(points, dtype=torch.float32)
t = rearrange(t, 'b d -> b () d')
hash_vectors(t, n_buckets=2), hash_vectors(t, n_buckets=2, n_rounds=5)
In the multiround case, the result from each hashing round is stacked along the 1 dimension, and an offset is added so each one has a unique index, from [0 to n_rounds * n_hases -1], [0-9] in this case.
In the transformer setting the q and k matrix shapes will be: [bs, sl, hidden_dim]
t = torch.randn(64, 512, 128)
out = hash_vectors(t, n_buckets=4, n_rounds=1)
out.shape, out.min(), out.max()
out = hash_vectors(t, n_buckets=4, n_rounds=3)
out.shape, out.min(), out.max()
The next parts we need to add are:
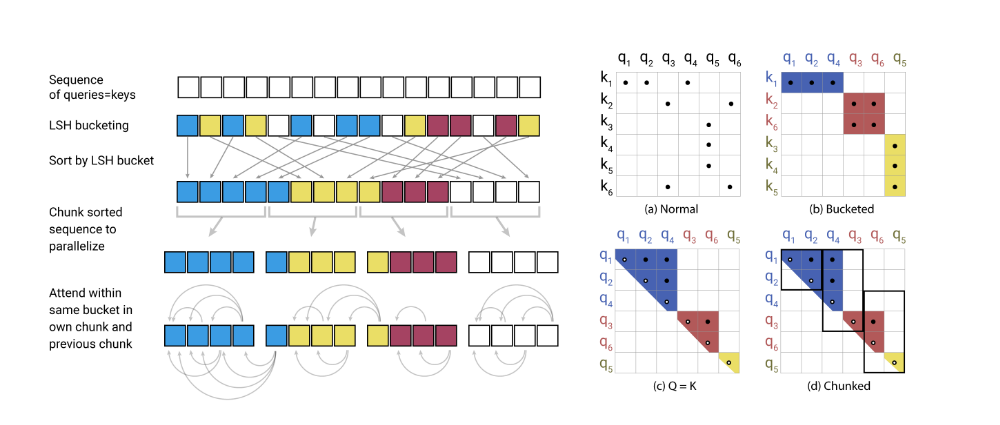
- sort first for bucket id, next for position in original sequence
- chunk buckets to some given size
- concatenate chunk with previous chunk to allow for inbetween attention
- calculate attention and output per (concatenated) chunk
- unsort everything and return
Let's set up some data to test - with a bs of 1 for sake of simplicity
k = torch.randn(1, 512, 128)
buckets = hash_vectors(k, n_buckets=4, n_rounds=1)
buckets[0,:10]
The number of vectors in each bucket:
torch.unique(buckets, return_counts=True)
We have 512 vectors of dim 128 to sort according to bucket:
k[0,:,:].shape
tmp = torch.arange(5*3).reshape((5,3))
tmp
We can sort along a specified axis, and get the index of the sorted item in the original tensor
v, i = tmp.sort(dim=1, descending=True)
v
i
And use the indices to get our original order back:
i[:,i[0]]
But how do we sort by some other index? We can slice according to the indices of the sorted buckets:
reorder = [2,0,1]
tmp[:,reorder]
Let's get indexes of the sorted buckets tensor and use that to reorder k:
v, i = buckets.sort(dim=-1)
v[:,:5], v[:,-5:], i[:,:5]
And finally reorder our k. Since we have a batch dimension (0) we have sorted along dim(1) - the rows.
k[:,i[0],:]
We can verify that the first item above is the same as the index i[:,0] of our k:
k[:,i[:,0],:10]
We also have to maintain order with respect to the orginial sequence order. So every k in bucket 0 have to be resorted according to it's original place in the sequenze.
Chunking to equal size is straight forward. Remove the batch dimension and chunk along the sequence dimension:
chunks = k.squeeze().chunk(4, dim=0)
k.shape, len(chunks), chunks[0].shape
We can get the attention from a chunk (assuming k=v) the normal way, ignoring attention heads and batch dimension for the moment. We also must make sure that a chunk can attend to the prvious chunk. For chunk 1 this means concatenation with chunk 0, before attention is calculated:
k0, k1, *_ = chunks
k0.shape, k1.shape
k_01 = torch.cat((k0,k1),0)
k_01.shape
attn = (k_01@k_01.T).softmax(-1)
attn.shape
attn[0,:].sum()
There are some important steps we still need to account for. From the paper:


That means we still have to:
- set h(kj) = h(qj)
- vectors in each chunk have to be sorted according to order in the original sequence
- mask out attention to not attend to it's own position (except when no other targets exist)
We have a rough idea of the implementation steps, so let's see if we can find a minimal solution based on the implementation by lucidrains. Once again will try to strip away as much as possible to leave a minimal solution for clarity:
- no dropout
- no padding or casusal masking (only masking relevant to LSH)
- don't return attn matrix
- don't account for duplicate attention (unsure about this)
- don't detach tensors where we don't need gradients
# boundaries might occur in the middle of a sequence of items from the
# same bucket, so this increases the chances of attending to relevant items.
def look_one_back(x):
x_extra = torch.cat([x[:, -1:, ...], x[:, :-1, ...]], dim=1)
return torch.cat([x, x_extra], dim=2)
def sort_key_val(t1, t2, dim=-1):
values, indices = t1.sort(dim=dim)
t2 = t2.expand_as(t1)
return values, t2.gather(dim, indices)
def batched_index_select(values, indices):
last_dim = values.shape[-1]
return values.gather(1, indices[:, :, None].expand(-1, -1, last_dim))
def max_neg_value(tensor):
return -torch.finfo(tensor.dtype).max
def chunked_sum(tensor, chunks=1):
*orig_size, last_dim = tensor.shape
tensor = tensor.reshape(-1, last_dim)
summed_tensors = [c.sum(dim=-1) for c in tensor.chunk(chunks, dim=0)]
return torch.cat(summed_tensors, dim=0).reshape(orig_size)
TOKEN_SELF_ATTN_VALUE = -5e4 # carefully set for half precision to work
Let's step through the forward() of the LSHAttention layer (below), to see if we can makes sense of it. We start with random test data. We assume q=k, and pass along v as well:
bs, sl, dim = 64, 512, 256
qk, v = torch.randn((bs, sl, dim)), torch.randn((bs, sl, dim))
qk.shape, v.shape
Grouping is done by hash_vector(). We'll test 6 rounds with 16 buckets.
n_buckets, n_rounds = 16, 6
buckets = hash_vectors(qk, n_buckets, n_rounds)
buckets.shape
buckets[0,:20]
Note that our bucket ids are unique within their hash group. I.e. the first and second hash group has non overlaping bucket ids:
buckets[0, 0:sl].unique(), buckets[0, sl:2*sl].unique()
The ticker is an index into the original sequence id:
ticker = torch.arange(n_rounds * sl).unsqueeze(0).expand_as(buckets)
ticker
Note that the id is not reset between hash groups:
ticker[0, sl-5:sl+5]
But by taking the mod of sl, we can get the sequence id in each hash round:
(ticker % sl)[0, sl-5:sl+5]
Or the id of the hash round by integer division with sl
(ticker//sl)[0, sl-5:sl+5]
In the lsh layer we make a buckets_and_t index. It's the bucket id scaled by sl + ticker % sl. Let's inspect the first component:
buckets[0,:10]
We scale it by muliplying with sl:
sl*buckets[0,:10]
Then we add ticker%sl which is the the sequence id (see above)
# we add the bucket id scaled by seqlen
# shape: [bs, (seqlen*buckets)]
# let us sort according to bucket id and index in sequence
buckets_and_t = sl * buckets + (ticker % sl)
buckets_and_t
Buckets_and_t is an index that takes both hash group id and sequence id into account, on the form bucket_id*sl + sequence id. The first item can take one of 16 values (n_buckets):
idxs = [idx*sl + 0 for idx in range(n_buckets)]
print(idxs)
For the second position we add 1 to offset for the sequence id:
print([idx+1 for idx in idxs])
And we can recreate the original ids from buckets_and_t:
(buckets_and_t[0,:20] - ticker[0,:20])/sl
buckets[0,:20]
Buckets_and_t is a unique index:
len(buckets_and_t[0,:]), len(buckets_and_t[0,:].unique())
It's also non overlapping between hash groups - the max id of the first group is smaller than the min id of the second group:
buckets_and_t[0,:sl].max(), buckets_and_t[0,sl:sl*2].min()
Next we sort buckets_and_t. Since we scaled the id's, hash groups are autmatically sorted.
sbuckets_and_t, sticker = sort_key_val(buckets_and_t, ticker, dim=-1) # shapes are [bs, seqlen*n_hashes]
sbuckets_and_t[0,:20]
sticker are the ids from our original buckets_and_t. That is, when we unsort sbuckets, sticker gives us the index of where the items belong in buckets_and_t.
sticker[0,sl:sl+10]
We can use sticker to look up items in buckets_and_t to create sbuckets_and_t, but not the other way around!
buckets_and_t[0,sticker[0,-10:]], sbuckets_and_t[0,-10:]
But we must also be able to undo this sorting. By doing a normal sort on the sticker list, we get a set of ids that tells us where an item belong in the original buckets_and_t:
_, undo_sort = sticker.sort(dim=-1) # indexes to undo sortings
We can use the gather function to recreate buckets_and_t from the sorted buckets. And we already know we can recreate seqlen id and hash group id from buckets_and_t
sbuckets_and_t.gather(-1, undo_sort)
(sbuckets_and_t.gather(-1, undo_sort)[0,0:20] - ticker[0,:20])/sl
buckets[0,:20]
To recap:
sbuckets_and_tis a "double index" sorted by both hash group id and sequence id- we can use
undo_sortto recreatebuckets_and_t, which is an index of hash_group and sequence id in the original order - we can use
buckets_and_tto get the original bucket ids in their respective hash groups, i.e.buckets
The next step is to extract the relevant vectors from our input. First we take the sticker mod with sl to produce the sequence id for each hash group. This gives us the id of qk and v to look up:
st = (sticker % sl) # index of [0..seqlen-1] for each hash round (n_hashes)[bs, seqlen*n_hashes]
st
We then lookup the vectors according to their (sorted) seqlen id:
sqk = batched_index_select(qk, st) # get the sorted qk, [bs, seqlen, model_dim]
sv = batched_index_select(v, st) # get the sorted v, [bs, seqlen, model_dim]
sqk.shape, sv.shape
sqk and sv now contains the input vectors sorted by hash group and seqlen id. Next we calculate the number of chunks. We assume chunks of even size, regardless of how many vectors are actually in a particular group:
n_chunks = n_rounds * n_buckets
n_chunks
Each chunk has a size along the sl dimension (chunk_size) of:
sqk.shape[1]/n_chunks, sl/n_buckets
Next we reshape both the st index, sqk and sv to add the n_chunks dimension.
We operate with one index for the query, and a another (duplicate) for k and v:
# get the qk and v chunks and also the indexes to undo sort later
bq_t = bkv_t = torch.reshape(st, (bs, n_chunks, -1)) # [bs, n_chunks, chunk_size]
bq_t.shape
bqk = torch.reshape(sqk, (bs, n_chunks, -1, dim)) # [bs, n_chunks, chunk_size, model_dim]
bv = torch.reshape(sv, (bs, n_chunks, -1, dim)) # [bs, n_chunks, chunk_size, model_dim]
bqk.shape, bv.shape
The next step it to split k and v. We normalize k but not q. This is mentioned in the paper:

bq = bqk
bk = F.normalize(bqk, p=2, dim=-1).type_as(bq)
bq[..., :].mean(), bk[...,:].mean()
Next we add the previous chunk as described in the paper, but only for k and v:
bk = look_one_back(bk) # [bs, n_chunks, chunk_size*2, model_dim]
bv = look_one_back(bv) # [bs, n_chunks, chunk_size*2, model_dim]
bkv_t = look_one_back(bkv_t) # [bs, n_chunks, chunk_size*2, model_dim]
Note that bq and bk now have different shapes:
bk.shape, bq.shape
dots = torch.einsum('bnsd,bnzd->bnsz',
bq, # [bs, n_chunks, chunk_size, model_dim]
bk # [bs, n_chunks, chunk_size*2, model_dim]
) * (dim ** -0.5) # dots: [bs, n_chunks, chunk_size, chunk_size*2]
dots.shape

self_mask = bq_t[:, :, :, None] == bkv_t[:, :, None, :]
self_mask.shape # [bs, n_chunks, chunk_size, chunk_size*2]
We achieve this by comparing the sorted and chunked buckets index with each other for k and q respectively. If they are equal we mask them.
bq_t[:, :, :, None][0,0,:10,0], bkv_t[:, :, None, :][0,0,0,:10]
self_mask[0,0,:5,:5]
self_mask[0,0,...].shape, self_mask[0,0,...].sum()
dots.masked_fill_(self_mask, TOKEN_SELF_ATTN_VALUE)
del self_mask
According to the appendix of the paper we need to avoid double counting q/k pairs over multiple rounds of hashing.

The lucidrains implementation mentions two strategies to deal with this, where only the first one is implemented, and seems to align with the paper:
The default is to count how many times a query-key pair is repeated, and to lower its log-prob correspondingly at each repetition
Note that this implementation does not fold this term into the mask (like the paper), but calculates it separately.
The goal is to consider each attention chunk (i.e. our input sorted by hash bucket id, and sequence id, and split in to n_chunks). For each chunk we have to assess:did a one particular key/query pair end up in similar attention chunks in a later hash round. If so we can argue that the model might "over focus" on this particular q/k pair, and that regularizing it (penalizing) probably makes sense.
First of all, we will be subracting the counts from dots, so they should have a similar shape in the end. We also expect the max count to be 6 (n_rounds).
dots.shape # [bs, n_chunk, chunk_size, chunk_size*2]
Consider item [0,0] in the first attention chunk (in eg. the 0th sample of the batch dimension). It ended up here because of the sorting. I.e. it must have had bucket number 0, and a pretty low sequence id (let's call it x_id) to end up as the first item (in this particular round). But in the next hash rounds it will get a different bucket id, and thus a different location in the sorting for that particular round. We have to associate the item from the input sequence,x_id, with our item[0,0] from the first hash round, and track where this item (x_id) in the original input sequence ended up in later hash rounds.
Also note that it dosen't have to be identical attention chunks, just similar. So if [k32, q34] end up in the attention chunk 44 in the first round, 88 in the second, but 44 and 33 in the third, our count will be 2.
First we need to create an index which tells us at which attention chunk a particular item in the input end up in in each hash round. Note that undo_sort is the key to take our sorted vectors back to original order. Eg. undo_sort[0,0] tells us where in the original sequence the item that ended up as item 0 after sorting belongs:
undo_sort[0,:10], undo_sort[0,sl:sl+10]
undo_sort tells us the sequence id where the sorted items will move to. Consider item 50 in our sorted sequences. It comes from various spots in the original input sequence in each of the 6 hash rounds, depending on which bucket it happend to fall into:
[undo_sort[0,s_id + 50].item() for s_id in range(0,sl*6, sl)]
If we take the mod of sl, we get the item's location within the original sequence at each hash round. And after sorting they end up at index 50.
[undo_sort[0,s_id + 50].item()%sl for s_id in range(0,sl*6, sl)]
If we instead take the mod of chunk_size (32 in this case), we get an index of which of the 96 chunks (n_rounds*n_buckets) the items ends up in. That means that the 50th element in the sorted sequences will end up in the following attention chunks:
[undo_sort[0,s_id + 50].item()//32 for s_id in range(0,sl*6, sl)]
We can do this for all items, and thus create a locs1 id that gives us an item's attention chunk id.
locs1 = undo_sort // bq_t.shape[-1] # same as chunk size
locs1.shape, locs1.min(), locs1.max()
Eg. items 0-5 in the sorted sequences end up in various attention chunks depending on which hash round we are in:
[locs1[0,slen:slen+5] for slen in range(0,sl*n_rounds, sl)]
We divided attention in even chunks, so bucket_id and attention chunk id won't always match:
buckets[0,sl:sl+5], locs1[0,sl:sl+5]
Next we create an id that is offset by one, except when it overflows our maximum id of 95, by taking the mod. We need this since our keys will be twice the size of the queries, and come from the neighbouring chunk.
95%n_chunks, 96%n_chunks, 97%n_chunks
locs2 = (locs1 + 1) % n_chunks
locs2.shape
This means that the combination of locs1 and 2 gives us ids to neighbour chunks.
locs1[0,-15:], locs2[0,-15:]
Next we reshape locs1 and locs2 to [bs, n_rounds, sl], concatenate them along the n_rounds dim, and switches the n_rounds and sl axis.
# locs1 = buckets * chunk_size + locs1
# locs2 = buckets * chunk_size + locs2
locs = torch.cat([
torch.reshape(locs1, (bs, n_rounds, sl)),
torch.reshape(locs2, (bs, n_rounds, sl)),
], 1).permute((0, 2, 1))
locs.shape # [bs, sl, n_rounds*2]
This means that the item that happende to be first in the sorted sequences ends up in various chunks depending on which hash bucket it ends up in in each round since this will affect it's sorting. The last half of the list is the neighbour chunks to our item:
locs[0, 0,:]
This is just a reshaped version of locs1:
[locs1[0,slen] for slen in range(0,sl*n_rounds, sl)]
But we have to get the attention chunk id for the original sequence order We can achieve this by looking up the locs according to st. st is our chunking key, and we used it to reorder our input kq and v into the sorted order. We can now reorder locs in the same way:
slocs = batched_index_select(locs, st)
slocs.shape # [bs, sl*n_rounds, n_rounds*2]
We now have the original order. This means that the first item in the original input sequence ends up in the following chunks (+ neighbours).
slocs[0,0,:]
s prefix to denote the result after sorting. This time we have sorted the sorted sequence (and is back to the original order...)We reshape slocs to include the n_chunks dimension:
b_locs = torch.reshape(slocs, (bs, n_chunks, -1, 2 * n_rounds))
b_locs.shape # [bs, n_chunks, chunk_size, n_round * 2]
We read this as the 0th element in the batch, the 0th attention block, and the 0th element. Which attention blocks did that particular element end up in in subsequent hash rounds (+ neighbours):
b_locs[0,0,0,:]
For the first element in chunck id 55, we get the following. Note that chunk 55 comes from the 3rd hash round (55//n_buckets).
b_locs[0,55,0,:]
Next we slice the first half of b_locs, and add unit axis at -2. This is for later comparison purposes.
b_locs1 = b_locs[:, :, :, None, :n_rounds]
b_locs1.shape # [bs, n_chunks, chunk_size, 1, n_rounds]
We copy b_locs1 along the 1 axis. This will be our query indexes Remember that we have 2x keys compared to queries.
bq_locs = b_locs1.expand(b_locs.shape[:3] + (2, n_rounds))
bq_locs.shape # [bs, n_chunks, chunk_size, 2, n_rounds ]
(bq_locs[:,:,:,0,:]==bq_locs[:,:,:,1,:]).unique()
bq_locs is now "doubled" in size, so it should be suitable to compare to the keys chunk locations:
bq_locs[0,0,0,:,:]
Next, we reshape to [bs, n_chunks, chunk_size, n_rounds*2]
bq_locs = torch.reshape(bq_locs, b_locs.shape)
bq_locs.shape # [bs, n_chunks, chunk_size, n_rounds*2]
This means that bq_locs is similar to our b_locs except for the final half:
bq_locs[0,0,0,:], b_locs[0,0,0,:]
To recap:
bq_locslet's us inspect each attention chunk to see which attention chunk one particular query ended up in at later hash rounds:
Next we need our k (similar to v) chunk ids. We use our b_locks and append the previous chunk, similar to the attention calculation.
bkv_locs = look_one_back(b_locs)
bkv_locs.shape # [bs, n_chunks, chunk_size*2, n_rounds]
Note that we appended the chunk along the -2 dimension:
b_locs.shape
Our key locs are offset by one in the second half to reflect the neighbour chunk:
bkv_locs[0,0,0,:]
The final step is to count elements that have ended up in the same chunk, and thus can attend to each other. Let's try for the first chunk:
bq_locs.shape, bkv_locs.shape
In attention chunk 0, key 3 and query 24 has landed in the following chunks over the rounds, with 1 match:
bkv_locs[0,0,3,:], bq_locs[0,0,24,:], (bkv_locs[0,0,3,:]==bq_locs[0,0,24,:]).sum()
But by adding appropriate unit axis, we can make sure that the sl dimensions don't overlap and broadcast's along each other:
(bq_locs[0, 0, :, None, :].shape,
bkv_locs[0, 0, None, :, :].shape,
(bq_locs[0, 0, :, None, :] == bkv_locs[0, 0, None, :, :]).shape)
We compare all elements:
dup_counts = (bq_locs[:, :, :, None, :] == bkv_locs[:, :, None, :, :])
dup_counts.shape # [bs, n_chunks, chunk_size, chunk_size*2, n_rounds]
dup_counts[0,0,3,24,:]
And sum across the last dimension:
tmp = dup_counts.sum(-1)
tmp.shape
For memory considerations the summation is chunked
dup_counts = chunked_sum(dup_counts, chunks=(n_rounds * bs))
dup_counts.shape # [bs, n_chunks, chunk_size, chunk_size * 2]
But it's the same as summing along -1:
torch.all(tmp==dup_counts)
dup_counts[0,0,:10,:10]
Notice that the diagonal in the first block equals number of hash rounds. This makes sense sinse i,i pairs are indentical and always come in the same chunk - we will mask them later. But this is not the case of the other half of the keys (from neighbour chunk):
dup_counts[0,0,:10,32:42]
Dup_counts and dots should now be of same shapes:
assert dup_counts.shape == dots.shape
dots.shape, dup_counts.shape
Finally we extract the log values of our duplicate counts from the self attention value dots as described in the paper's appendix:
dots = dots - torch.log(dup_counts + 1e-9)
del dup_counts
masked_value = max_neg_value(dots)
We can pass along pad masks if our input is of variable length and padded. We don't wan't the model to see the pad token. Since our original input has been sorted and chunked, we have to sorte the masks similar:
input_mask = torch.ones((bs, sl)).bool()
input_mask.shape
In case the input_mask is is shorter than input, this pads to appropriate shape with the value True:
#if input_mask is not None:
input_mask = F.pad(input_mask, (0, sl - input_mask.shape[1]), value=True)
input_mask.shape
We reorder the sequence with st and reshapes to include the n_chunks dimension. This gives us the mask for q
mq = input_mask.gather(1, st).reshape((bs, n_chunks, -1))
mq.shape
The mask for k is similar, but includes the neighbour chunk as usual.
mkv = look_one_back(mq)
mkv.shape
We add unit axis for comparision across the final dimensions of q and k:
mask = mq[:, :, :, None] * mkv[:, :, None, :]
mask.shape
dots.masked_fill_(~mask, masked_value)
dots
#del mask
del mask
Add casual masking to not allow the model to peek into future tokens. Mask if query comes after key in input sequence.
bq_t[0,55,:]
bkv_t[0,55,:]
# if self.causal:
mask = bq_t[:, :, :, None] < bkv_t[:, :, None, :]
mask.shape
Since the tokens are sorted before masking, the masking is not triangular like in the base transformer: in this case all tokens after 220 should be masked (True):
[(t,m) for t,m in zip(bkv_t[0,55,:], mask[0,55,0,:])]
#mask = mask & (bkv_t[:, :, None, :] < query_len)
dots.masked_fill_(mask, masked_value)
del mask
The paper states: While attention to the future is not allowed, typical implementations of the Transformer do allow a position to attend to itself. Such behavior is undesirable in a shared-QK formulation because the dot-product of a query vector with itself will almost always be greater than the dot product of a query vector with a vector at another position. We therefore modify the masking to forbid a token from attending to itself, except in situations where a token has no other valid attention targets (e.g. the first token in a sequence).
Recall that bq_t and bkc_t is the look up key we use to reorder input qk and v into sorted and chunked order. The diagonal of the first part of k is eg. always similar to q. We have to compare all elements with each other (32*64)
bq_t[0,0,:], bkv_t[0,0,:]
We achieve this by adding appropriate unit axis (se section below):
bq_t[:, :, :, None].shape, bkv_t[:, :, None, :].shape
self_mask = bq_t[:, :, :, None] == bkv_t[:, :, None, :]
self_mask.shape, self_mask[0,0,...].sum()
dots.masked_fill_(self_mask, TOKEN_SELF_ATTN_VALUE)
By adding appropriate unit axis, we can compare all elements of the final dimension of a tensor
a, b = torch.arange(2), torch.arange(5)
a.shape, b.shape
a, b, a[None,:]+b[:,None], a[:,None]+b[None,:]
Note: The paper sugests NOT attenting across buckets: Now we turn to LSH attention, which we can think of in terms of restricting the set Pi of target items a query position i can attend to, by only allowing attention within a single hash bucket. Lucidrains' inmplementation sets this to True by default however.
We will only run this part of the code if we want to restrict attention across buckets.
First we get the hasbucket by integer dividing by sl. Note that hasbucket ids are consecutive across hash rounds (not overlapping in each round). We also reshape to n_chunks:
#if not self._attend_across_buckets:
bq_buckets = bkv_buckets = torch.reshape(sbuckets_and_t // sl, (bs, n_chunks, -1))
bq_buckets.shape
Eg. attention chunk 1 has a mix of buckets 0 and 1:
bq_buckets[0,1,:]
We add previous chunk to the keys:
bkv_buckets = look_one_back(bkv_buckets)
bkv_buckets.shape
bkv_buckets[0,1,:]
bucket_mask = bq_buckets[:, :, :, None] != bkv_buckets[:, :, None, :]
bucket_mask.shape
bq_buckets[0,1,-1], bkv_buckets[0,1,:]
bucket_mask[0,1,-1,:]
dots.masked_fill_(bucket_mask, masked_value)
del bucket_mask
We take the softmax with the logsumexp trick:
dots_logsumexp = torch.logsumexp(dots, dim=-1, keepdim=True)
dots = torch.exp(dots - dots_logsumexp).type_as(dots)
dots.shape
dots[0,0,0,:].sum()
And finally compute our self attention:
bo = torch.einsum('bnsz,bnzd->bnsd',
dots, # [bs, n_chunks, chunk_size, chunk_size*2]
bv) # [bs, n_chunks, chunk_size*2, model_dim]
bo.shape # [bs, n_chunks, chunk_size, model_dim]
The final step is to reconstruct the batched, chunked and sorted q, k and v back to our original representation. First we reshape the contextualised values to remove the n_chunks dimension. It's still sorted though:
First we reshape self-attnetion to remove the n_chunks dimension. It's still sorted though:
so = torch.reshape(bo, (bs, -1, dim)) # [bs, seqlen*n_rounds, model_dim]
so.shape
Then we unsort so by looking up our unsort keys undo_sort.
o = batched_index_select(so, undo_sort)
o.shape
And reshapes it to include a n_rounds dimension:
o = torch.reshape(o, (bs, n_rounds, sl, dim)) # [bs, n_rounds, sl, dim]
o.shape
Then the same steps for the logits (dots_logsumexp):
slogits = torch.reshape(dots_logsumexp, (bs, -1,)) # [bs, seqlen*n_rounds]
slogits.shape
logits = slogits.gather(1, undo_sort)
logits.shape # [bs, seqlen*n_rounds]
logits = torch.reshape(logits, (bs, n_rounds, sl, 1))
logits.shape # [bs, n_rounds, sl, 1]
We take the softmax over the n_rounds dimension, "averaging" the contribution to self-attention over each hashing round.
probs = torch.exp(logits - torch.logsumexp(logits, dim=1, keepdim=True))
probs.shape # [bs, n_rounds, sl, 1]
So summing over the n_rounds dimension equals 1:
probs[0,:,0,0].sum()
And our final self-attention weighted by contribution from each round:
out = torch.sum(o * probs, dim=1) # [bs, sl, dim]
out.shape, qk.shape, v.shape
class LSHAttention(nn.Module):
def __init__( self, bucket_size = 64, n_hashes = 8):
super().__init__()
self.bucket_size = bucket_size
self.n_hashes = n_hashes
def forward(self, qk, v, **kwargs):
batch_size, seqlen, dim, device = *qk.shape, qk.device
#pdb.set_trace()
# f'Sequence length ({seqlen}) needs to be divisible by target bucket size x 2 - {self.bucket_size * 2}'
assert seqlen % (self.bucket_size * 2) == 0
# Get buckets. We use the above method
n_buckets = seqlen // self.bucket_size
buckets = hash_vectors(qk, n_buckets, self.n_hashes) # buckets: [bs, (sl * n_hashes)]
# We use the same vector as both a query and a key.
assert int(buckets.shape[1]) == self.n_hashes * seqlen
# a vector of [bs, n_hashes*seqlen), where ticker[0,:]= [0,1,2, ..-, seqlen*n_hash-1]
ticker = torch.arange(self.n_hashes * seqlen, device=device).unsqueeze(0).expand_as(buckets)
# ticker % seqlen = [o...seqlen-1, 0...seqlen-1, ...] n_bucket times
# we add the bucket id scaled by seqlen
# shape: [bs, (seqlen*buckets)]
# let us sort according to bucket id and index in sequence
buckets_and_t = seqlen * buckets + (ticker % seqlen)
# disable gradients for tensor
#buckets_and_t = buckets_and_t.detach()
# Hash-based sort ("s" at the start of variable names means "sorted")
sbuckets_and_t, sticker = sort_key_val(buckets_and_t, ticker, dim=-1) # shapes are [bs, seqlen*n_hashes]
_, undo_sort = sticker.sort(dim=-1) # indexes to undo sortings
del ticker
st = (sticker % seqlen) # index of [0..seqlen-1] for each hash round (n_hashes)[bs, seqlen*n_hashes]
sqk = batched_index_select(qk, st) # get the sorted qk, [bs, seqlen, model_dim]
sv = batched_index_select(v, st) # get the sorted v, [bs, seqlen, model_dim]
# Split off a "bin" axis so that attention only occurs within chunks.
# get the qk and v chunks and also the indexes to undo sort later
n_chunks = self.n_hashes * n_buckets
bq_t = bkv_t = torch.reshape(st, (batch_size, n_chunks, -1)) # [bs, n_chunks, chunk_size]
bqk = torch.reshape(sqk, (batch_size, n_chunks, -1, dim)) # [bs, n_chunks, chunk_size, model_dim]
bv = torch.reshape(sv, (batch_size, n_chunks, -1, dim)) # [bs, n_chunks, chunk_size, model_dim]
# Hashing operates on unit-length vectors. Unnormalized query vectors are
# fine because they effectively provide a learnable temperature for the
# attention softmax, but normalizing keys is needed so that similarity for
# the purposes of attention correctly corresponds to hash locality.
bq = bqk
bk = F.normalize(bqk, p=2, dim=-1).type_as(bq)
## attent to previous chunk as well - append previous chunk, cat along dim=2 (the sl dimension)
bk = look_one_back(bk) # [bs, n_chunks, chunk_size*2, model_dim]
bv = look_one_back(bv) # [bs, n_chunks, chunk_size*2, model_dim]
bkv_t = look_one_back(bkv_t) # [bs, n_chunks, chunk_size*2, model_dim]
# Dot-product attention
dots = torch.einsum('bnsd,bnzd->bnsz',
bq, # [bs, n_chunks, chunk_size, model_dim]
bk # [bs, n_chunks, chunk_size*2, model_dim]
) * (dim ** -0.5) # dots: [bs, n_chunks, chunk_size, chunk_size*2]
# Mask out attention to self except when no other targets are available.
self_mask = bq_t[:, :, :, None] == bkv_t[:, :, None, :]
dots.masked_fill_(self_mask, TOKEN_SELF_ATTN_VALUE)
del self_mask
# Softmax.
dots_logsumexp = torch.logsumexp(dots, dim=-1, keepdim=True)
dots = torch.exp(dots - dots_logsumexp).type_as(dots)
# calculate self-attention (attn * values)
bo = torch.einsum('bnsz,bnzd->bnsd', dots, bv) # [bs, n_chunks, chunk_size, model_dim]
# unchunk, unsort and reshape self-attention
so = torch.reshape(bo, (batch_size, -1, dim)) # [bs, seqlen*n_hashes, model_dim]
o = batched_index_select(so, undo_sort) # [bs, seqlen*n_hashes, model_dim]
o = torch.reshape(o, (batch_size, self.n_hashes, seqlen, dim)) # [bs, n_hashes, seqlen, model_dim]
# unchunk, unsort and reshape logits
slogits = torch.reshape(dots_logsumexp, (batch_size, -1,)) # [bs, seqlen*n_hashes]
logits = slogits.gather(1, undo_sort) # [bs, seqlen*n_hashes]
logits = torch.reshape(logits, (batch_size, self.n_hashes, seqlen, 1)) # [bs, n_hashes, seqlen, 1]
# average probabilites across hash rounds (dim 1) and get weighted attention
probs = torch.exp(logits - torch.logsumexp(logits, dim=1, keepdim=True)) # [bs, n_rounds, seqlen, 1]
out = torch.sum(o * probs, dim=1) # [bs, seqlen, model_dim]
# return output and bucket distribution
return out, buckets
qk = torch.randn(64, 512, 128)
v = torch.rand(64, 512, 128)
lsh_att = LSHAttention()
out, buckets = lsh_att(t, v)
out.shape, buckets.shape