
from fastai.text.all import *
from torch.utils.data import Dataset
from reformer_fastai.transformer import TransformerLM
from reformer_fastai.reformer import LSHLM
We want to create sequences of the form 0w0w, where w is a sequence of integeres between 1-127 of some lenght: eg. 08470847. We create items on the fly instead of all items up front. We return a tuple to make the dataloader a bit easier to inspect.
class TwinSequence(Dataset):
def __init__(self, sl=1024, len=100):
assert sl%2 == 0
self.sl = sl
self.len = len
def __getitem__(self, idx):
seq = torch.randint(1,128,(self.sl//2,)) # w: [1-127] of len sl//2
seq[0] = 0 # seq = 0w
seq = torch.cat((seq,seq), -1) # seq = 0w0w
target = torch.cat((seq[1:],torch.tensor([0])), -1) # return offset target x:[0123], y:[1230]
return (seq, target)
def __len__(self):
return self.len
dls = DataLoaders.from_dsets(TwinSequence(10, 50), bs=6, shuffle=False, device='cuda')
xb, yb = dls.one_batch()
xb.shape, yb.shape
Note that the final target item is a padded 0. But that should also be predicitable from the first part of the input sequence:
xb[0].tolist(), yb[0].tolist()
The number of batches in train data loader (n_iter in fastai lingo): The reformer paper mentions 150 k steps. One step is one iteration/batches.
len(dls.train)
We have to mask the first half of the targets. The first part is just random integers, so it's impossible to learn anything from it. We set the tokens in the first part to a special index, -100, and later tell our lossfunction to ignore items with this value. This means that the only task the model can learn is to copy the first part of the input sequence. If we didn't mask the first part, it would be penalized for poor performance in the first part, and would try to find a compromise.
class MaskTargCallback(Callback):
def before_batch(self):
self.y[:, :self.dls.train_ds.sl//2] = -100
We create a custom accuracy that also disregards tokens with value -100:
def masked_accuracy(inp, targ, ignore=-100):
pred = inp.argmax(dim=-1)
mask = targ[0] != ignore
return (pred[:,mask] == targ[:,mask]).float().mean()
pred = torch.tensor([ 0, 1, 2, 3, 4,1,2,3,4,55])[None,:]
targ = torch.tensor([-100,-100,-100,-100,-100,1,2,3,4,0])[None,:]
mask = targ[0] != -100
(pred[:,mask] == targ[:,mask]).float().mean()
And finally a callback to inspect items directly before modelling:
class Inspect_items(Callback):
def after_batch(self):
if self.iter==0 and self.epoch==0 and self.training:
inp = self.learn.x[0].tolist()
targ = self.learn.y[0].tolist()
df = pd.DataFrame((inp,targ)).T
df.columns = ['inp', 'targ']
print(df)
Let's check what's actually going into the model with a tiny example:
bs, sl = 64,16
n_epochs = 1
train_sz = 500
valid_sz = 100
dls = DataLoaders.from_dsets(TwinSequence(sl, train_sz), TwinSequence(sl, valid_sz), bs=bs, shuffle=False, device='cuda')
model = TransformerLM(128, 256, d_ff=256, n_layers=1, n_heads=4, max_seq_len=sl, pos_enc='fixed',
attn_dropout=0, ff_dropout=0, emb_dropout=0)
learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(ignore_index=-100),
metrics=masked_accuracy, cbs=[MaskTargCallback(), Inspect_items()])
learn.fit(1, 1e-3)
Looks good!
First we will test a short sequence to test that everything is working. We use the TransformerLM and compares it to the LSHLM. Note that LSHLM has the same LSHAttention as the ReformerLM, but less the other reformer memory tricks.
bs, sl = 64,64
n_epochs = 1
train_sz = 50_000
valid_sz = 10_000
dls = DataLoaders.from_dsets(TwinSequence(sl, train_sz), TwinSequence(sl, valid_sz), bs=bs, shuffle=False, device='cuda')
Total training steps:
len(dls.train)*n_epochs
model = TransformerLM(128, 256, d_ff=256, n_layers=1, n_heads=4, max_seq_len=sl, pos_enc='fixed',
attn_dropout=0, ff_dropout=0, emb_dropout=0)
learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(ignore_index=-100),
metrics=masked_accuracy, cbs=[MaskTargCallback()])
learn.fit_one_cycle(n_epochs, 1e-3)
learn.recorder.plot_loss()

The model fairly quickly learns the copy task, and reaches near 0 loss within a few hundred steps
x = dls.train_ds[0][0].cuda()
x = x[None]
x[:,x.size(1)//2:], x[:,x.size(1)//2:].shape
learn.model.store_attention()
with torch.no_grad():
out = learn.model(x)
preds = out.argmax(-1)[:,x.size(1)//2:]
(preds[:,:-1]==x[:,x.size(1)//2+1:]).float().mean()
attn = learn.model.get_attention_matrix()
We have 4 heads in our transformer, and 1 attention matrix per head:
The attention matrices shows us that mid way through the sequence the model starts paying attention to the first input sequence as expected. Each layers learns a bit different, but the combined output is good enough for perfect sequence copying. Note that there is no pattern to learn before this point, so the attention is just random noise. We also see that no token peeks ahead of it's own location, which we would expect from a language model with causal attention.
fig, axs = plt.subplots(1, 4, sharey=True, figsize=(16, 16))
for ax, mat in zip(axs, attn[0][0]):
ax.matshow(mat)

del learn
torch.cuda.empty_cache()
Note! Sequence length sl needs to be divisible by bucket_sizex2. So e.g. sl=64 -> bucket_size=32
n_hashes=4
bucket_size = 32
assert sl % (bucket_size * 2) == 0
model = LSHLM(vocab_sz=128, d_model=256, n_layers=1, n_heads=4, max_seq_len=sl,
bucket_size=bucket_size, n_hashes=n_hashes, causal=True)
learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(ignore_index=-100),
metrics=masked_accuracy, cbs=[MaskTargCallback()])
learn.fit_one_cycle(n_epochs, 1e-3)
learn.recorder.plot_loss()

del learn
torch.cuda.empty_cache()
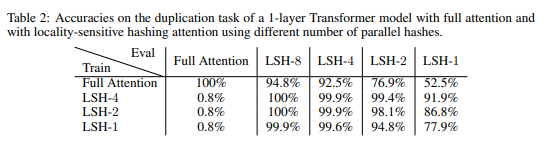
Let's see if we can train a model with full attention and evaluate with LSH-1.
model = LSHLM(vocab_sz=128, d_model=256, n_layers=1, n_heads=4, max_seq_len=sl,
bucket_size=bucket_size, n_hashes=n_hashes, causal=True,
use_lsh=False) # disable LSH
learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(ignore_index=-100),
metrics=masked_accuracy, cbs=[MaskTargCallback()])
learn.fit_one_cycle(n_epochs, 1e-3)
Validation with full attention:
learn.model.use_lsh
%%time
learn.validate()
Let's reset use_lsh to True
learn.model.use_lsh=True
learn.model.use_lsh
%%time
learn.validate()
As expected validation with full attention performs better and faster
Increase the sequence length to 1024, similar what is used in the paper.
bs, sl = 32,1024
n_epochs = 4
train_sz = 50_000
valid_sz = 10_000
dls = DataLoaders.from_dsets(TwinSequence(sl, train_sz), TwinSequence(sl, valid_sz), bs=bs, shuffle=False, device='cuda')
Total training steps:
len(dls.train)*n_epochs
model = TransformerLM(128, 256, d_ff=256, n_layers=1, n_heads=4, max_seq_len=sl, pos_enc='fixed',
attn_dropout=0, ff_dropout=0, emb_dropout=0)
learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(ignore_index=-100),
metrics=masked_accuracy, cbs=[MaskTargCallback()])
learn.fit_one_cycle(n_epochs, 1e-3)
learn.recorder.plot_loss()

del learn
torch.cuda.empty_cache()
The model learns the task perfectly, similar to the result reported in the paper.
n_hashes=4
bucket_size = 64
assert sl % (bucket_size * 2) == 0
model = model = LSHLM(vocab_sz=128, d_model=256, n_layers=1, n_heads=4, max_seq_len=sl,
bucket_size=bucket_size, n_hashes=n_hashes, causal=True)
learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(ignore_index=-100),
metrics=masked_accuracy, cbs=[MaskTargCallback()])
learn.fit_one_cycle(n_epochs, 1e-3)
learn.recorder.plot_loss()

del learn
torch.cuda.empty_cache()
The model struggles compared to full attention. The paper mentions 99.9% accuracy for this setup, but trained the model for 150k steps - much longer than in this case.
We do a test similar to the one above, but just using a single hashing round in LSH.
n_hashes=1
bucket_size = 64
assert sl % (bucket_size * 2) == 0
model = LSHLM(vocab_sz=128, d_model=256, n_layers=1, n_heads=4, max_seq_len=sl,
bucket_size=bucket_size, n_hashes=n_hashes, causal=True)
learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(ignore_index=-100),
metrics=masked_accuracy, cbs=[MaskTargCallback()])
learn.fit_one_cycle(n_epochs, 1e-3)
learn.recorder.plot_loss()

del learn
torch.cuda.empty_cache()
Similar performance as above.